世間は5連休ですが、特に出かけることもできず、日曜大工や電子工作の材料も入手ができずと普段休日にやっていることをほぼ封じられている毎日です。しょうがないので、前から触ってみたかったReactを使って、前から欲しいと思っていた電子書籍管理アプリを作ってみたレポートです。
仕事ではないので、特に事前調査などをせずに行き当たりばったりでコードを書いていきます。また、このレポート記事も(仕事ではないので)Twitter並みに雑にやった作業を書いていきます(ちなみに、記事を書いているのはリアルタイムではありません。メモ書きはリアルタイムでやっていますが、整理・校正は5日目にまとめてやっています)。
さて、作成するアプリの要件は次のとおり。
- いわゆる「自炊」で作成した電子書籍ファイルを管理する
- 電子書籍ファイルの形式はPDFと画像が入ったフォルダをZIP形式で圧縮したものの2種類
- 指定したディレクトリ内の電子書籍ファイルの表紙(1ページ目)のサムネイルをタイル状に表示する
- サムネイルをダブルクリックするとビューアが起動してそのファイルを開く
将来的にメタデータによる管理などもできると良いのだが、まずは動くものを実装することと、Reactの全体像やアーキテクチャを掴むことを目標にする。そのため、パフォーマンスについてはあまり気にしない。ただ、ある程度正しいアーキテクチャというものは意識してコードを書いていく。
開発環境の構築&Reactの概要を掴む
まずはReactのチュートリアル(https://reactjs.org/tutorial/tutorial.html)をざっと眺めるとともに、このチュートリアル内の「Setup Option 2: Local Development Environment」を参照して「npx create-react-app <アプリ名>」コマンドで開発環境を作る。Reactの特徴は、表示するコンポーネントをクラスとして定義して、そこにHTMLのテンプレートを直接書き込む点にあるようだ。今回は「ebmgr」という名前でアプリを作る。
$ npx create-react-app ebmgr
ちなみにnpxコマンドはNode.jsのパッケージマネージャであるnpmコマンドに同梱されているもので、指定されたパッケージのインストールとそこに含まれているコマンドの実行を同時に行うというもの。
create-react-appで作成されたディレクトリ内のsrcディレクトリ内にソースコードが、publicディレクトリ内に開発用Webによって公開されるindex.htmlや画像、CSSなどが配置されている。
$ ls
README.md node_modules package-lock.json package.json public src
$ ls public/
favicon.ico index.html logo192.png logo512.png manifest.json robots.txt
$ ls src/
App.css App.test.js index.js serviceWorker.js
App.js index.css logo.svg setupTests.js
とりあえずチュートリアルの指示に従って「npm start」コマンドを実行してみると、Webブラウザで作成したアプリケーションの雛形が動いた。index.html内にはJavaScriptファイルやCSSファイルを読み込むようなタグは入っていないので、それらはテストサーバーが動的に挿入している模様。
また、srcディレクトリ以下のApp.jsを見てみると、そこにブラウザで表示されているアプリケーションのHTMLコードが直接記述されている。これを変更して保存すると、リアルタイムでブラウザの画面がそれに追従して更新される。便利。
import React from 'react';
import logo from './logo.svg';
import './App.css';
function App() {
return (
<div className="App">
<header className="App-header">
<img src={logo} className="App-logo" alt="logo" />
<p>
Edit <code>src/App.js</code> and save to reload.
</p>
<a
className="App-link"
href="https://reactjs.org"
target="_blank"
rel="noopener noreferrer"
>
Learn React
</a>
</header>
</div>
);
}
export default App;
ちなみにこのようにJavaScript中に直接HTMLが書き込まれているフォーマットをJSXと呼ぶらしい。
JSXファイル内ではSVGファイルやCSSファイルをimport文でインポートできるようだ。また、テンプレート内での変数展開は「{」「}」で行える模様。一般的なテンプレートエンジンはforやwhileのようなループ機構を持っているが、JSXはそういった機構は持っていないようなので、たとえばArrayで格納されているテキストを順に表示したいといった場合、単純にJavaScriptコードで次のように展開してやれば良い。
function App() {
const items = ["foo", "bar", "hoge"];
const listItems = this.state.items.map(x => <li key={x}>{x}</li>);
return (
<div className="ThumbnailGrid">
<ul>{listItems}</ul>
</div>
);
}
このApp.jsというのは「App」というコンポーネントを定義しているだけで、ページ全体のレンダリングはindex.jsによって行われている模様。コードをみると、このReactDOM.render()メソッドで表示する内容や、HTML内でそれを挿入するDOM要素を指定している。
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
import * as serviceWorker from './serviceWorker';
ReactDOM.render(
<React.StrictMode>
<App />
</React.StrictMode>,
document.getElementById('root')
);
まずは電子書籍のサムネイル画像をグリッド表示させたいので、App.jsをコピーして「ThumbnailGrid.js」というファイルを作る。
import React from 'react';
function ThumbnailGrid() {
const items = ["foo", "bar", "hoge"];
const listItems = this.state.items.map(x => <li key={x}>{x}</li>);
return (
<div className="ThumbnailGrid">
<ul>{listItems}</ul>
</div>
);
}
export default ThumbnailGrid;
index.jsを編集し、このThumbnailGrid.jsをインポートした上でと記述されていたものをに差し替えてみる。無事動作。ついでに今回ServiceWorkerは使わないのでそれ関連のコードを削除。
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import ThumbnailGrid from './ThumbnailGrid';
ReactDOM.render(
<React.StrictMode>
<ThumbnailGrid />
</React.StrictMode>,
document.getElementById('root')
);
Reactアプリに表示する情報を取得するためのAPIをOpenAPIで実装する
ReactではNode.jsのモジュールをインポートできるようだが、さすがにfsなどのモジュールは使えないようだ。そのため、ローカルファイルシステム上にあるファイルの情報などを表示するにはREST APIなどを使ってサーバーと別途非同期通信を行う必要がある。create-react-appで作成した環境では「npm start」コマンドを実行すると開発用サーバーが立ち上がるが、この開発用サーバーはReactアプリを提供する機能しかないため、別途APIを提供するWebサーバーを用意する必要がある。
最近ではREST APIといえばOpenAPI(https://www.openapis.org)ですよね、ということでOpenAPI Specification(https://swagger.io/specification/)を見ながら電子書籍データのリソースを定義した最低限のサービス仕様ファイルを作成する。ここでは「/books」にGETリクエストを投げることで、タイトルとファイルパスを含む配列を返すというAPIを定義した。
openapi: 3.0.5
info:
title: ebook manager (ebmgr) App
description: ebook manager API
version: 0.1.0
servers:
- url: http://localhost:3333/api/v1
description: Local server
paths:
/books:
get:
description: Returns all books list
operationId: getBooks
responses:
"200":
description: A list of books
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/Book'
x-content-type: application/json
x-swagger-router-controller: Default
components:
schemas:
Book:
type: object
properties:
title:
type: string
description: title of book
example: some interesting title
path:
type: string
description: virtualized path of book
example: /foo/bar/baz
example:
title: some interesting title
path: /foo/bar/baz
なお、あとでツールを使ってここからサーバーコードを生成するのだが、ここで定義している「operationId」という要素がメソッド名にマッピングされる。省略すると勝手にダサい名前をつけられる可能性があるので気をつけましょう。
Swagger Editor(https://editor.swagger.io)に作成したサービス仕様ファイルをアップロードすると、ここで作成したスキーマを検証したり、「Generate Server」や「Generate Client」メニューからサーバー/クライアントコードをダウンロードできるようになる。今回はNode.jsでサーバーも書くので「nodejs-server」を選択。するとzip圧縮されたサーバーコードがダウンロードされる。
api-serverというディレクトリを作ってダウンロードしたzipファイルを展開して、そこで「npm start」コマンドを実行するとindex.jsファイルが実行されAPIサーバーが立ち上がる。なおこのサーバーはexpressを利用して実装されているようだ。標準では3000番ポートで待受をするが、これはReactの開発サーバーとバッティングするので3333番ポートに変更している。
const path = require('path');
const http = require('http');
const oas3Tools = require('oas3-tools');
const serverPort = 3333;
// OAS3 API server
const options = {
controllers: path.join(__dirname, './controllers')
};
const oasDefinition = path.join(__dirname, 'api/openapi.yaml');
const expressAppConfig = oas3Tools.expressAppConfig(oasDefinition, options);
expressAppConfig.addValidator();
const app = expressAppConfig.getApp();
http.createServer(app).listen(serverPort, function () {
console.log('Your server is listening on port %d (http://localhost:%d)', serverPort, serverPort);
console.log('Swagger-ui is available on http://localhost:%d/docs', serverPort);
});
サービス仕様に記述したパスに対応する処理はservice/DefaultServices.jsに書けば良いようだ。将来的にこのapi-server以下のコードは書き直すことがあるかもしれないので、実際のロジックはこのディレクトリ外のファイル(../../ebmgr.js)に記述する。
まず必要なのは指定したディレクトリ内にある電子書籍ファイルの情報を返すコードなので、getContents()というメソッドを実装する(コード全文はこちら)。
function getContents() {
const targetDirs = config.contentDirectories;
var results = [];
for (const dir of targetDirs) {
const r = searchContents(dir);
results = results.concat(r);
}
return results;
}
function searchContents(dirname) {
const dirnameHash = getHash(dirname);
const r = [];
_searchContents(dirname, dirnameHash, r);
return r;
function _searchContents(dirname, dirnameHash, results) {
const dir = fs.readdirSync(dirname, {withFileTypes: true});
const exts = config.targetExtentions;
for (const item of dir) {
if (item.isDirectory()) {
_searchContents(path.join(dirname, item.name),
path.join(dirnameHash, item.name),
results);
continue;
}
for (const ext of exts) {
if (item.name.endsWith(ext)) {
const metadata = {};
metadata.title = path.basename(item.name, ext);
metadata.path = path.join(dirnameHash, item.name);
results.push(metadata);
continue;
}
}
}
}
}
exports.getContents = getContents;
これを、service/DefaultService.js内で呼び出す。
const ebmgr = require('../../ebmgr.js');
/**
* Returns all books list
*
* returns List
**/
exports.getBooks = function() {
return new Promise(function(resolve, reject) {
const items = ebmgr.getContents();
resolve(items);
});
}
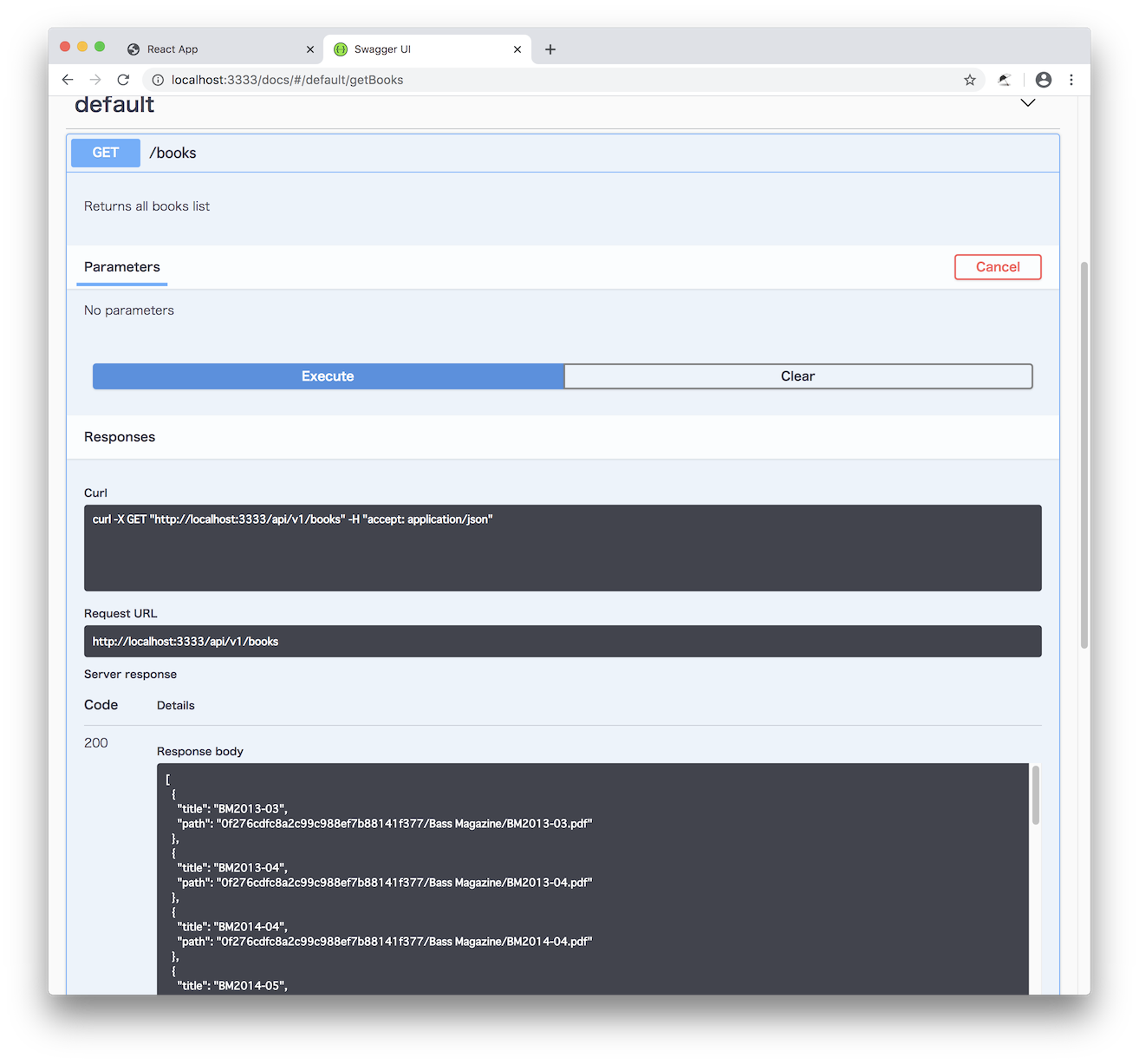
Swagger Editorから生成されたサーバーコードは、デフォルトでSwagger的な機能が有効になるように設定されており、api-serverディレクトリで「npm start」(もしくは「node index.js」)コマンドでサーバーを起動し、Webブラウザでそのサーバーの/docs/以下にアクセスすることで、リソース一覧を確認したり、フォームで引数を指定してリソースにアクセスすることができる。これで試したところ、とりあえず目的のデータは得られているようだ。
ついでにAPIサーバー(今回は3333番ポートを使用)からReactの開発サーバー(3000番ポートを使用)にアクセスできるようAPIサーバーにリバースプロクシを設定。これでこのAPIサーバーに対する/docs/以下と/api/以下以外のアクセスはすべてReactの開発サーバー(localhost:3000)に転送される(コード全文)。
const { createProxyMiddleware } = require('http-proxy-middleware');
const app = expressAppConfig.getApp();
// add routes for React
app.use(/^\/(?!(docs|api)\/).*/, createProxyMiddleware({ target: 'http://localhost:3000', changeOrigin: true }));
続いてはReactアプリ側でAPIを呼び出すコードの実装。Swagger Editorにはクライアントコードを生成する機能もあるのだが、「Generate Client」-「javascript」でダウンロードしたコードをReact内のコードから呼び出そうとしたらWebpackのエラーで動かない。雑にググったところ、「swagger-client」というものを使えという話があったのでこちらをReactアプリのディレクトリ内でnpmコマンドを実行してインストール。
$ npm i swagger-client
今回は「ThumbnailGrid」コンポーネント内で電子書籍ファイルのサムネイル画像を表示させたいので、このコンポーネントを定義しているThumbnailGrid.js内でswagger-clientをimportする。
import React, {Component} from 'react';
import SwaggerClient from 'swagger-client';
あとはThumbnailGrid()メソッド内でこのクライアントを使ってgetBooks APIを叩いてデータを取得し、それをHTMLとしてレンダリングすれば良いのだが、このクライアントは結果を非同期で(Promiseを使って)返す仕組みになっている。つまり単純にメソッドの返り値として取得したデータを返すことはできない。ということでググると、コンポーネントをReact.Componentクラスの派生クラスとして定義することで色々非同期に処理ができるようになるようだ。
コンポーネントのライフサイクルなどはVue.jsでも登場した概念でほぼ同じ。最初にconstructor()が→render()→copmponentDidMount()という順序で実行される。コンポーネント固有のデータはconstructor()内で定義したstateオブジェクトで管理するようだ。ということで、copmponentDidMount()内でswagger-client経由で電子書籍データのgetを実行することにする。
swagger-clientは初期化時にサービス仕様定義ファイルを与えるようになっているが、こちらはAPIサーバーの/api-docsからGETできる。
componentDidMount() {
const client = new SwaggerClient('http://localhost:3333/api-docs');
client.then(c => {
c.apis.default.getBooks().then(results => {
this.setState({ items: results.body,
loading: false,
});
});
});
}
ReactではsetState()メソッドでstateを更新するようになっており、これに応じてrender()メソッドが実行されてコンポーネントの再レンダリングが実行される。UIライブラリではよくある設計ですね。
ということで、render()メソッドにstateオブジェクトを元にコンテンツをレンダリングする処理を記述する。
render() {
const listItems = this.state.items.map(x => <li key={x.title}>{x.title}</li>);
return (
<div className="ThumbnailGrid">
<ul>{listItems}</ul>
</div>
);
}
また、constructor()でstateの初期化をしておく。
class ThumbnailGrid extends Component {
constructor () {
super();
this.state = { items: [],
loading: true,
};
}
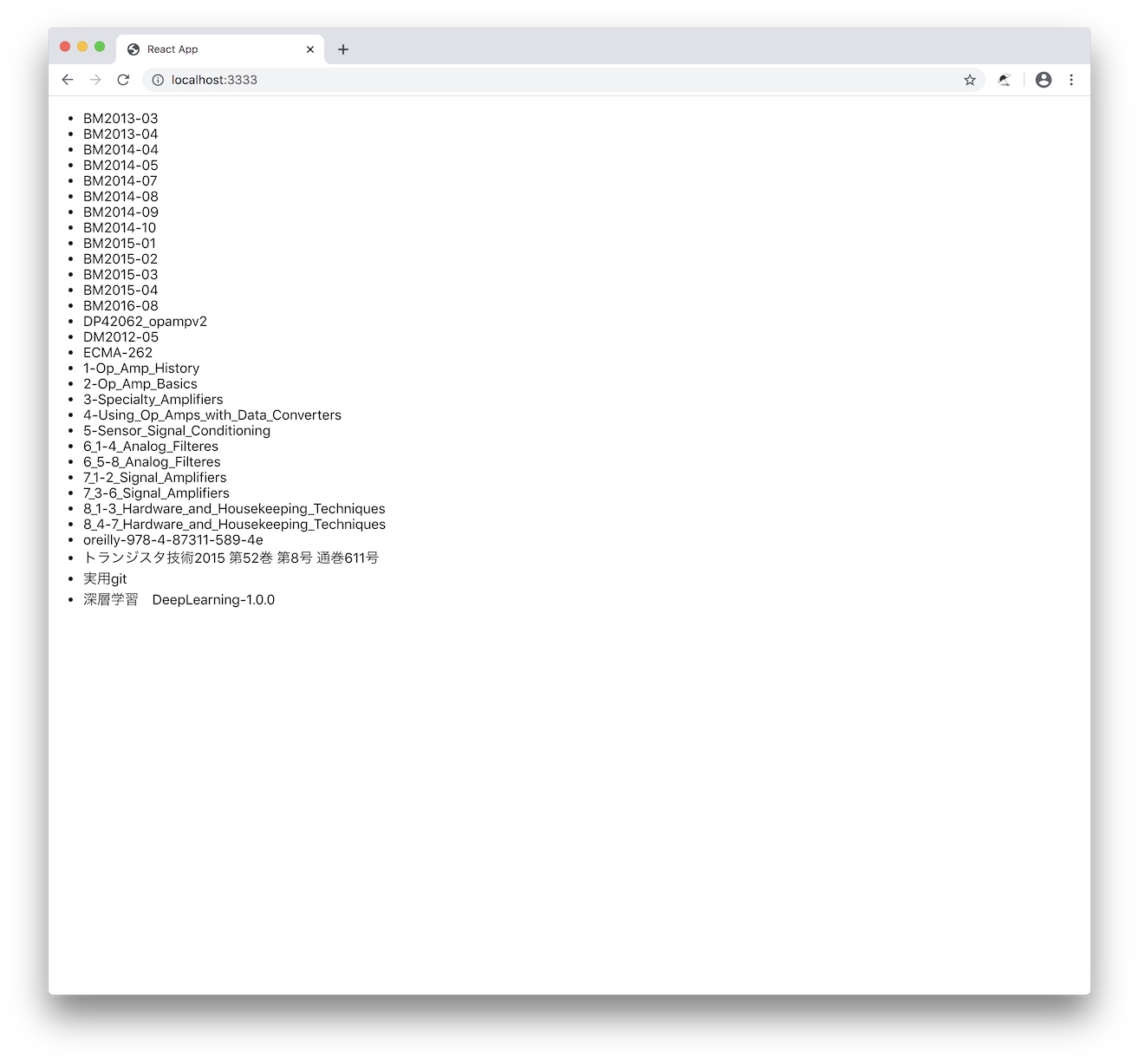
これでReactの開発サーバーとAPIサーバーを動かして、APIサーバーにアクセスするととりあえずファイルのタイトル(ファイル名)一覧が表示される。
1日目はここまで。本日の作業時間は4時間ほど。